Pages 179-218 of Kernel Projects for Linux by Gary Nutt.
Tuesday 5/31/2005 by 11:00 PM PST.
The file system you will work with, JOSFS, is much simpler than most "real" file systems, but it is powerful enough to provide the standard "basic" features: reading and writing files organized in a hierarchical directory structure. Our file system currently does not support hard links, symbolic links, time stamps, or special device files like most UNIX file systems do. JOSFS is an in-memory file system, meaning that the data "on disk" is actually stored entirely in main memory. This means that changes made to the file system are not saved after the machine is rebooted.
Most UNIX file systems divide available disk space into two main types of regions: inode regions and data regions. UNIX file systems assign one inode to each file in the file system; a file's inode holds critical meta-data about the file such as its stat attributes and pointers to its data blocks. The data regions are divided into much larger (typically 8KB or more) data blocks, within which the file system stores file data and directory meta-data. Directory entries contain file names and pointers to inodes; a file is said to be hard-linked if multiple directory entries in the file system refer to that file's inode. Since our file system will not support hard links, we do not need this level of indirection and therefore can make a convenient simplification: our file system will not use inodes at all, but instead we will simply store all of a file's (or sub-directory's) meta-data within the (one and only) directory entry describing that file.
Both files and directories logically consist of a series of data blocks, which may be scattered throughout the disk much like the pages of a process's virtual address space can be scattered throughout physical memory.
Most disks cannot perform reads and writes at byte granularity, but can only perform reads and writes in units of sectors, which today are almost universally 512 bytes each. File systems actually allocate and use disk storage in units of blocks. Be wary of the distinction between the two terms: sector size is a property of the disk hardware, whereas block size is an aspect of the operating system using the disk. A file system's block size must be at least the sector size of the underlying disk, but could be greater.
The original UNIX file system used a block size of 512 bytes, the same as the sector size of the underlying disk. Most modern file systems use a larger block size, however, because storage space has gotten much cheaper and it is more efficient to manage storage at larger granularities. Our file system will use a block size of 4096 bytes.
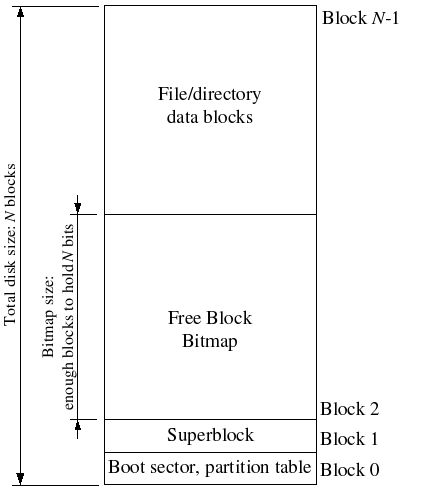
File systems typically reserve certain disk blocks, at "easy-to-find" locations on the disk such as the very start or the very end, to hold meta-data describing properties of the file system as a whole, such as the block size, disk size, any meta-data required to find the root directory, the time the file system was last mounted, the time the file system was last checked for errors, and so on. These special blocks are called superblocks.
Our file system will have exactly one superblock, which will always be at block 1 on the disk. Its layout is defined by struct josfs_super in josfs.h. Block 0 is typically reserved to hold boot loaders and partition tables, so file systems generally never use the very first disk block. Most "real" file systems maintain multiple superblocks, replicated throughout several widely-spaced regions of the disk, so that if one of them is corrupted or the disk develops a media error in that region, the other superblocks can still be found and used to access the file system.
In the same way that the kernel must manage the system's physical memory to ensure that a given physical page is used for only one purpose at a time, a file system must manage the blocks of storage on a disk to ensure that a given disk block is used for only one purpose at a time. In file systems it is common to keep track of free disk blocks using a bitmap rather than a linked list, because a bitmap is more storage-efficient than a linked list and easier to keep consistent. Searching for a free block in a bitmap can take more CPU time than simply removing the first element of a linked list, but for file systems this isn't a problem because the I/O cost of actually accessing the free block after we find it dominates for performance purposes.
To set up a free block bitmap, we reserve a contiguous region of space on the disk large enough to hold one bit for each disk block. For example, since our file system uses 4096-byte blocks, each bitmap block contains 4096*8=32768 bits, or enough bits to describe 32768 disk blocks. In other words, for every 32768 disk blocks the file system uses, we must reserve one disk block for the block bitmap. A given bit in the bitmap is set if the corresponding block is free, and clear if the corresponding block is in use. The block bitmap in our file system always starts at disk block 2, immediately after the superblock. For simplicity we will reserve enough bitmap blocks to hold one bit for each block in the entire disk, including the blocks containing the superblock and the bitmap itself. We will simply make sure that the bitmap bits corresponding to these special, "reserved" areas of the disk are always clear (marked in-use).
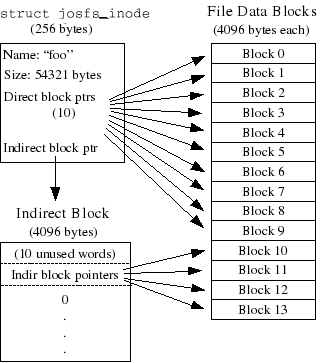
The layout of the meta-data describing a file in our file system is described by struct josfs_inode in josfs.h. This meta-data includes the file's name, size, type (regular file or directory), and pointers to the blocks comprising the file.
The block array in struct josfs_inode contains space to store the block numbers of the first 10 (JOSFS_NDIRECT) blocks of the file, which we call the file's direct blocks. For small files up to 10*4096 = 40KB in size, this means that the block numbers of all of the file's blocks will fit directly within the josfs_inode structure itself. For larger files, however, we need a place to hold the rest of the file's block numbers. For any file greater than 40KB in size, therefore, we allocate an additional disk block, called the file's indirect block, to hold up to 4096/4 = 1024 additional block numbers. To keep bookkeeping simple, we leave the first 10 numbers in the indirect block unused. Thus, the 10th block number is the 10th slot in the indirect block (rather than the 0th, as might be done if we were being very space-efficient). Our file system therefore allows files to be up to 1024 blocks, or four megabytes, in size. To support larger files, "real" file systems typically support double- and triple-indirect blocks as well.
A josfs_inode structure in our file system can represent either a regular file or a directory; these two types of "files" are distinguished by the type field in the josfs_inode structure. The file system manages regular files and directory-files in exactly the same way, except that it does not interpret the contents of the data blocks associated with regular files at all, whereas the file system interprets the contents of a directory-file as a series of josfs_inode structures describing the files and subdirectories within the directory.
The superblock in our file system contains a josfs_inode structure (the s_root field in struct josfs_super), which holds the meta-data for the file system's root directory. The contents of this directory-file is a sequence of josfs_inode structures describing the files and directories located within the root directory of the file system. Any subdirectories in the root directory may in turn contain more josfs_inode structures representing sub-subdirectories, and so on.
The JOS file system you will develop is implemented as a kernel module in Linux. Your assignment will be to implement the routines that handle Free Block management, changing file sizes, read/write to the file, and reading a directory file.
Skeleton JOS file system code (lab3.tgz) will be provided to you on CourseWeb.
You will need to implement the following functions for this lab:
Free Block Map bookkeeping: allocate_block, free_block
Support for changing file sizes: change_size
Support for accessing files: josfs_read, josfs_write
Support for reading directories: josfs_dir_readdir
Challenge problems (optional):
Build steps
The resulting module knows how to provide access to the linked-in JOSFS image, but just loading the module doesn't make the file system available. The script "runjosfs.sh" will perform the necessary steps to make the file system available. You must first *mount* the file system on an existing directory. This hides the directory's existing contents, turning the directory into a "gateway" into the new file system. After loading JOSFS, the "./runjosfs.sh" script mounts that file system onto the "test" directory. When your file system is ready, "$ls base" and "$ls test" should return the same results (except for things like ownership, permissions, and inode numbers).
It is worth discussing how the functionality of the script is implemented. The following table shows the commands used:
| Installing a module in the kernel | $insmod josfs.ko |
| Checking to see if the module is installed | $lsmod |
| Mounting the filesystem to a directory in the Linux FS | $/bin/mount -t josfs none test |
| Unmounting the filesystem | $umount test |
| Removing a module from the kernel | $rmmod josfs |
sudo /root/fixMachine
sudo /root/runjosfs
After implementing these functions you should be able to the following in your filesystem. You will be able to do a read and write to files change the size of the file, and read the contents of a directory. Note: after the code is implemented, you will not be able to create or delete files, unless you have completed the challenge portions of the project.
Assume you have a file named hello.txt in the fs:
$ls test
|
read the contents of a directory |
$cat hello.txt
|
read the contents of a file |
$echo "Hello World CS111" > hello.txt
|
write data to an existing file |